Infini-Attention
Memory serves 内存服务是智能的基石,因为它可以根据定制的环境进行高效的计算,但对于Transformer 和基于Transformer的大模型来说,因为注意力机制的本质,它们都存在受限的上下文相关记忆。该注意力机制在内存和计算方面都是$O(n^2)$。对于使用标准的Transformer的大模型来说,扩大上下文记忆的序列,通常带来的经济成本很高
对于极长序列,压缩记忆系统有望比注意力机制更具可扩展性和效率,压缩存储器不是使用随输入序列长度而增长的数组,而是主要维护固定数量的参数来存储和调用具有有限存储和计算成本的信息。在压缩存储器中,通过更改其参数将新信息添加到存储器中,目的是以后可以恢复该信息
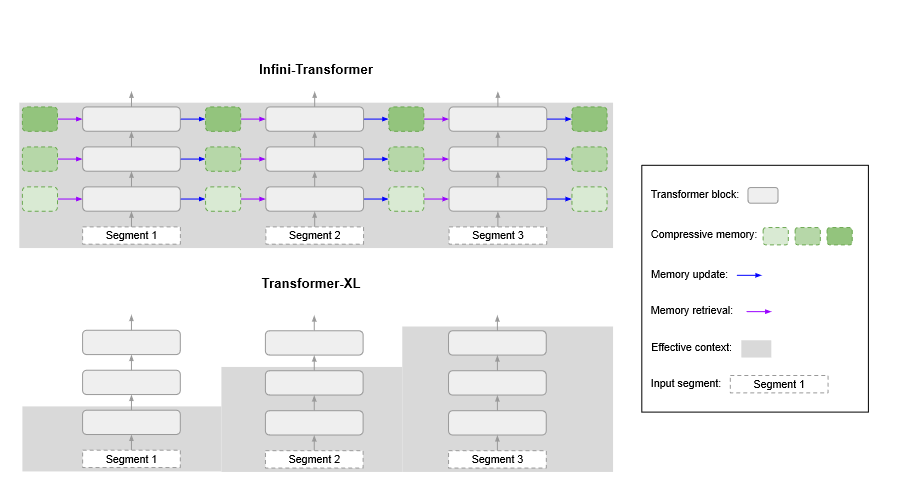
无限注意力(Infini-Attention)
无限注意力的基本概念: 在无限注意力模型中,我们用 Query (Q),去从一个记忆库 $M_{s-1}$ 中找到我们需要的信息。这个查询就像是一个搜索关键词,而记忆库则像是一个巨大的资料库。通过这个查询,我们可以从记忆库中提取我们需要的数据。使用查询 $Q \in \mathbb{R}^{N \times d_{\text{key}}}$ 从记忆 $M_{s-1} \in \mathbb{R}^{d_{\text{key}} \times d_{\text{value}}}$ 中检索新内容 $A_{\text{mem}} \in \mathbb{R}^{N \times d_{\text{value}}}$,公式为:
\[A_{\text{mem}} = \frac{\sigma(Q) M_{s-1}}{\sigma(Q) z_{s-1}}\]其实就像是在问记忆库一个问题,然后根据这个问题的关键词得到答案。 这里的 $\sigma$ $z_{s-1} \in \mathbb{R}^{d_{\text{key}}}$ 是非线性激活函数。非线性选择和规范化方法对训练稳定性至关重要。
记忆更新
更新记忆库: 当我们获取了需要的信息后,我们还会向记忆库中添加新的信息,这样记忆库就会不断更新,能够提供更多的、更精确的数据。这个过程就像是不断地给图书馆增加新书一样。将通过新的键值对(KV)条目更新记忆体和规范化项,并获得下一个状态:
\[M_s \leftarrow M_{s-1} + \sigma(K)^T V \quad \text{和} \quad z_s \leftarrow z_{s-1} + N \sum_{t=1}^N \sigma(K_t)\]新的记忆状态 $M_s$ 和 $z_s$随后传递到下一个片段 $S + 1$,在每个注意力层中构建递归关系。右侧的项 $\sigma(K)^T V$ 被称为关联绑定操作符。
受到Delta规则成功的启发,我们也将其融入到我们的无限关注机制中。Delta规则试图通过首先检索现有的值条目并在应用新的关联绑定作为新更新前从新值中减去它们来略微改进记忆更新:
\[M_s \leftarrow M_{s-1} + \sigma(K)^T (V - \frac{\sigma(K) M_{s-1}}{\sigma(K) z_{s-1}})\]这个更新规则(线性+Delta)在键值绑定已经存在于记忆中时保留关联矩阵不变,同时还跟踪与前一个规则(线性)相同的规范化项以保持数值稳定性。
长期上下文注入
长期记忆的注入: 我们不仅仅提取记忆库中已有的信息,还会结合当前的具体情况来调整这些信息。这里用到了一个“门控标量” $\beta$ ,它可以帮助我们决定要使用多少记忆库中的信息,以及多少当前的信息。这就像是在做蛋糕时调整原料比例,确保蛋糕既有好的味道,也有好的质地。调整公式为:
我们通过学习到的门控标量 $\beta$ 聚合本地注意力状态 $A_{\text{dot}}$ 和检索到的记忆内容 $A_{\text{mem}}$:
\[A = \text{sigmoid}(\beta) \odot A_{\text{mem}} + (1 - \text{sigmoid}(\beta)) \odot A_{\text{dot}}\]与传统多头注意力的比较: 这种无限注意力机制也采用了类似于常见的多头注意力模型中的技术,允许系统同时处理多个数据点,并最终合并成一个输出结果。这种处理方式使得模型可以同时关注多个方面的信息,提高处理效率。与标准的多头注意力(MHA)类似,对于多头无限关注,我们并行计算 $H$ 个上下文状态,然后串联并投影它们以得到最终的注意力输出 $O \in \mathbb{R}^{N \times d_{\text{model}}}$:
\[O = [A_1; \ldots; A_H] W_O\]其中 $W_O \in \mathbb{R}^{H \times d_{\text{value}} \times d_{\text{model}}}$ 是可训练的权重。
总结
- Infini-Transformers 在长语境语言建模任务中表现优于强基线模型,并在内存占用方面实现了超过100倍的压缩率。
- 参数为1B的Infini-Transformer解决了输入长度高达100万个词组的密钥检索任务,即使对更短的序列进行微调,也能显示出很强的长度泛化能力。
- 经过持续的预训练和微调,8B Infini-Transformer 在长度为500K的书籍摘要任务中取得了最先进的性能。通过可视化学习到的门控得分,揭示了专门处理局部或长期上下文的专门注意头的出现,以及两者兼而有之的混合注意头的出现。
Leave a comment