Flash Attention2
Flash Attention
扩大Transformer中上下文长度的规模是一个挑战,这是因为Attention layer的运行时间和内存需求是输入序列长度的二次方
\[\text{Complexity} = O(n^2 \cdot d)\] \[\text{Memory} = O(n^2)\]性能对比
尽管 FlashAttention 的计算速度是标准注意力机制(Standard Attention)的 2 到 4 倍,但其性能在 GPU 上的发挥并未完全达到理想状态:
- 前向推理能力:在 GPU 设备上,FlashAttention 的前向推理能力仅能达到理论 FLOPs(每秒浮点运算次数)的 30% 到 50%。
- 反向传播:在 A100 GPU 上,FlashAttention 的反向传播性能仅达到 25% 到 35%。
相比之下,优化后的矩阵乘法(GEMM)可以接近设备的理论最大吞吐量,达到 80% 到 90%。
原因分析
FlashAttention 在 GPU 上的性能局限性主要由以下因素导致:
- 工作分区不理想:在不同的线程块和 warp(扭曲)之间的工作分配不够理想,导致 GPU 占用率低。
- 共享内存的读写:过多不必要的共享内存读/写操作,降低了整体性能。
GPU 浮点数格式
现代 GPU 通常采用以下浮点数表示格式以优化性能和精度:
- FP16:半精度浮点数,常用于需要较高计算速度但可以容忍精度较低的应用场景。
- BF16:Brain Floating Point(脑浮点数),介于 FP16 和 FP32 之间的精度,特别适用于深度学习等领域。
这些浮点格式的选择对于达到 GPU 的最大计算效率至关重要。
Standard Attention Implementation
输入序列$Q, K, V \in \mathbb{R}^{N \times d}$ 其中$N$是输入序列的长度,$d$是head dimension
注意力机制计算
计算得分矩阵 $S$:
\[S = QK^T \in \mathbb{R}^{N \times N}\]应用 Softmax 函数:
\(P = \text{softmax}(S) \in \mathbb{R}^{N \times N},\) 其中$softmax$是逐行应用到矩阵$S$中
计算输出矩阵 $O$:
\[O = PV \in \mathbb{R}^{N \times d}\]backward pass的注意力处理
令$dO \in \mathbb{R}^{N \times d}$ 为 $O$ 关于某个损失函数的梯度。
应用链式法则计算反向传播:
输出矩阵$O$ 的梯度$dO$:
\[dO \in \mathbb{R}^{N \times d}\]这是我们的输出是已知的,可以根据这个计算其他的导数
值矩阵 $V$ 的梯度 $dV$
对于值矩阵 $V$ 的梯度计算如下:
\[dO = d(PV) = P \, dV \in \mathbb{R}^{N \times d}\]因此,$V$ 的梯度为:
\[dV = P^T dO \in \mathbb{R}^{N \times d}\]$P$ 的梯度 $dP$
对于 $P$ 的梯度计算如下:
\[dO = d(PV) = dP \cdot V + P \cdot dV\]因此,
\[dP = dO \cdot V^T\]$S$ 的梯度 $dS$
对于 $S$(softmax 函数的输出)的梯度计算如下:
\[dS = \text{softmax_grad}(P, dP)\]更明确地表示为:
\[dS = \text{dsoftmax}(dP) \in \mathbb{R}^{N \times N}\]$Q$ 的梯度 $dQ$
给定 $S = QK^T$,$Q$ 的梯度为:
\[dS = d(QK^T) = dQ \cdot K^T + Q \cdot dK^T\]因此,
\[dQ = dS \cdot K\]$K$ 的梯度 $dK$
最后,$K$ 的梯度计算为:
\[dK = Q^T \cdot dS\]标准注意力机制实现中的缺点
- 内存需求:
- 标准的注意力机制将矩阵 $S$ 和 $P$ 存储到 HBM(高带宽内存),这需要 $O(N^2)$ 的内存。
- 通常情况下,$N \gg d$,即 $N$ 在 1k–8k 的数量级,而 $d$ 通常在 64–128 之间。
- 计算流程:
- 步骤 1:调用矩阵乘法(GEMM)子程序,计算 $S = QK^T$,并将结果写入 HBM。
- 步骤 2:从 HBM 加载矩阵 $S$,计算 softmax,并将结果 $P$ 写入 HBM。
- 步骤 3:调用 GEMM,计算 $O = PV$。
- 性能瓶颈:
- 由于大多数操作受限于内存带宽,大量的内存访问会导致较慢的运行时间。
- 内存消耗:
- 需要物化矩阵 $S$ 和 $P$,导致内存需求为 $O(N^2)$。
- 必须保存 $P \in \mathbb{R}^{N \times N}$ 以用于反向传播计算梯度。
FlashAttention的实现
为了在硬件加速器(如 GPU)上加速注意力机制,减少内存的读写操作,同时保持相同的输出(无近似)。通过使用online softmax 的使用,减少了中间矩阵 $S$ 和 $P$ 写入 HBM(高带宽内存)的次数,从而实现了 2-4 倍的加速效果。
2.3.1 前向传播(Forward Pass)
FlashAttention 应用了经典的块分割(tiling)技术,以减少内存 IO 操作:
- 从 HBM 加载输入块到 SRAM;
- 针对这个块计算注意力;
- 更新输出,而不将大型的中间矩阵 $S$ 和 $P$ 写回 HBM。
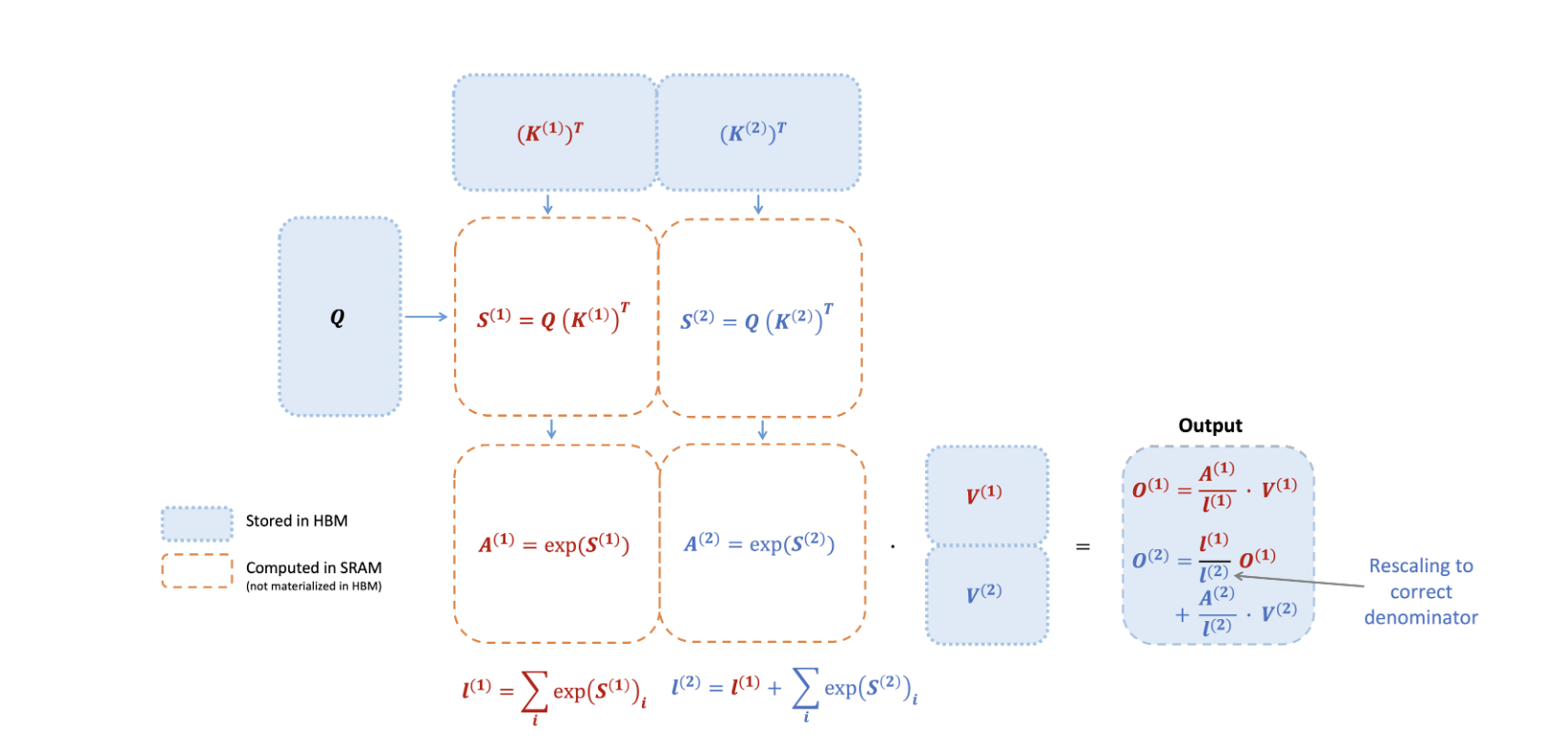
由于 softmax 操作将整行或整块耦合在一起,online softmax能将注意力计算拆分为多个块,并对每个块的输出进行重新缩放,最终得到正确的结果(无近似)。
通过显著减少内存的读写次数,FlashAttention 相比于优化后的基准注意力实现,实现了 2-4 倍的wall-clock时间加速。
online Softmax 技术
为简单起见,考虑注意力矩阵 $S$ 的一个行块,它的形式为 $[S(1), S(2)]$,其中 $S(1), S(2) \in \mathbb{R}^{B_r \times B_c}$,$B_r$ 和 $B_c$ 分别是行块和列块的大小。我们需要计算这个行块的 softmax,并与值矩阵 $V$ 相乘,其形式为 $[V(1), V(2)]$,其中 $V(1), V(2) \in \mathbb{R}^{B_c \times d}$。
标准的 softmax 计算步骤如下:
-
计算行块的最大值: \(m = \max(\text{rowmax}(S(1)), \text{rowmax}(S(2))) \in \mathbb{R}^{B_r}\)
-
计算行块的和: \(\ell = \text{rowsum}(e^{S(1) - m}) + \text{rowsum}(e^{S(2) - m}) \in \mathbb{R}^{B_r}\)
-
计算概率矩阵 $P$: \(P = \begin{bmatrix} P(1) & P(2) \end{bmatrix} = \text{diag}(\ell)^{-1} \begin{bmatrix} e^{S(1) - m} & e^{S(2) - m} \end{bmatrix} \in \mathbb{R}^{B_r \times 2B_c}\)
-
最终输出: \(O = \begin{bmatrix} P(1) & P(2) \end{bmatrix} \begin{bmatrix} V(1) \\ V(2) \end{bmatrix} = \text{diag}(\ell)^{-1} e^{S(1) - m} V(1) + e^{S(2) - m} V(2) \in \mathbb{R}^{B_r \times d}\)
online softmax 计算步骤如下:
- 第一块的 softmax 计算:
-
计算第一块矩阵 $S(1)$ 的行最大值: \(m(1) = \text{rowmax}(S(1)) \in \mathbb{R}^{B_r}\)
-
计算第一块的行和: \(\ell(1) = \text{rowsum}(e^{S(1) - m(1)}) \in \mathbb{R}^{B_r}\)
-
计算局部 softmax 矩阵: \(\tilde{P}(1) = \text{diag}(\ell(1))^{-1} e^{S(1) - m(1)} \in \mathbb{R}^{B_r \times B_c}\)
-
计算输出: \(O(1) = \tilde{P}(1) V(1) = \text{diag}(\ell(1))^{-1} e^{S(1) - m(1)} V(1) \in \mathbb{R}^{B_r \times d}\)
-
- 第二块的 softmax 计算与重新缩放:
-
计算第二块矩阵 $S(2)$ 的行最大值,与 $m(1)$ 进行比较: \(m(2) = \max(m(1), \text{rowmax}(S(2))) = m\)
-
计算重新缩放后的行和: \(\ell(2) = e^{m(1) - m(2)} \ell(1) + \text{rowsum}(e^{S(2) - m(2)}) = \text{rowsum}(e^{S(1) - m}) + \text{rowsum}(e^{S(2) - m}) = \ell\)
-
计算第二块的局部 softmax 矩阵: \(\tilde{P}(2) = \text{diag}(\ell(2))^{-1} e^{S(2) - m(2)}\)
-
计算最终输出,包含重新缩放的第一块输出和第二块输出: \(O(2) = \text{diag}(\ell(1) / \ell(2))^{-1} O(1) + \tilde{P}(2) V(2)\) \(O = \text{diag}(\ell(2))^{-1} e^{S(1) - m} V(1) + \text{diag}(\ell(2))^{-1} e^{S(2) - m} V(2) = O\)
-
FlashAttention 如何使用online softmax 以减少内存读写如下图所示
FlashAttention反向传播
-
避免存储大矩阵: 在反向传播过程中,FlashAttention 通过重新计算注意力矩阵 $S$ 和 $P$,避免存储这些大小为 $N \times N$ 的中间矩阵。这种方法节省了大量内存。
-
内存节省: 由于不需要保存大规模的中间矩阵 $S$ 和 $P$,根据序列长度 $N$,FlashAttention 可以节省 10-20 倍的内存。所需内存从与序列长度成二次方关系($O(N^2)$)降低到线性关系($O(N)$)。
-
时间加速: 由于减少了内存读写操作,反向传播的墙钟时间(wall-clock time)相比传统实现加速了 2-4 倍。
-
反向传播中的分块计算: 反向传播采用了与前向传播类似的分块技术,但概念上更加简单(不需要 softmax 重新缩放)。然而,反向传播的实现更加复杂,因为它涉及更多的矩阵乘法操作。
-
矩阵乘法的复杂性: 在反向传播过程中,需要在 SRAM 中存储更多的数据,因为反向传播需要进行 5 次矩阵乘法,而前向传播仅需要 2 次矩阵乘法。
FlashAttention 2 的实现
在硬件加速器(如 GPU)上进一步优化注意力机制,通过减少非矩阵乘法浮点运算(FLOPs),flashAttention2改进了online softmax 技术,同时保持相同的输出精度(无近似)。
3.1.1 前向传播(Forward Pass)
通过两项优化减少了非矩阵乘法的 FLOPs:
-
延迟重新缩放:在更新输出时,不需要对每个块的输出进行多次缩放。可以保持未缩放的版本 $\tilde{O}(2)$,并保留统计量 $\ell(2)$,直到循环的最后才对最终输出 $\tilde{O}(last)$ 进行缩放: \(\tilde{O}(2) = \text{diag}(\ell(1))^{-1} O(1) + e^{S(2) - m(2)} V(2)\)
最后,在循环的末尾进行缩放: \(O(last) = \text{diag}(\ell(last))^{-1} \tilde{O}(last)\)
-
减少存储需求:在反向传播中,只需要存储 logsumexp $L(j) = m(j) + \log(\ell(j))$,而不必分别保存最大值 $m(j)$ 和指数和 $\ell(j)$。
两个块的例子
online softmax 技术的优化计算过程如下:
- 第一块的 softmax 计算:
-
计算第一块矩阵 $S(1)$ 的行最大值: \(m(1) = \text{rowmax}(S(1)) \in \mathbb{R}^{B_r}\)
-
计算第一块的行和: \(\ell(1) = \text{rowsum}(e^{S(1) - m(1)}) \in \mathbb{R}^{B_r}\)
-
计算未缩放的输出: \(\tilde{O}(1) = e^{S(1) - m(1)} V(1) \in \mathbb{R}^{B_r \times d}\)
-
- 第二块的 softmax 计算与重新缩放:
-
计算第二块矩阵 $S(2)$ 的行最大值,与 $m(1)$ 进行比较: \(m(2) = \max(m(1), \text{rowmax}(S(2))) = m\)
-
计算重新缩放后的行和: \(\ell(2) = e^{m(1) - m(2)} \ell(1) + \text{rowsum}(e^{S(2) - m(2)}) = \text{rowsum}(e^{S(1) - m}) + \text{rowsum}(e^{S(2) - m}) = \ell\)
-
计算未缩放的输出: \(\tilde{O}(2) = \text{diag}(e^{m(1) - m(2)})^{-1} \tilde{O}(1) + e^{S(2) - m(2)} V(2)\)
-
最后,计算最终输出: \(O(2) = \text{diag}(\ell(2))^{-1} \tilde{O}(2) = O\)
-
算法 1: FlashAttention2 前向传播
输入要求:
- 矩阵 $Q, K, V \in \mathbb{R}^{N \times d}$ 存储在 HBM 中
- 块大小 $B_c, B_r$
步骤:
- 将 $Q$ 分割为 $T_r = \lceil \frac{N}{B_r} \rceil$ 个块 $Q_1, \dots, Q_{T_r}$,每个块大小为 $B_r \times d$,将 $K, V$ 分割为 $T_c = \lceil \frac{N}{B_c} \rceil$ 个块 $K_1, \dots, K_{T_c}$ 和 $V_1, \dots, V_{T_c}$,每个块大小为 $B_c \times d$
- 将输出 $O \in \mathbb{R}^{N \times d}$ 分割为 $T_r$ 个块 $O_1, \dots, O_{T_r}$,每个块大小为 $B_r \times d$,并将 logsumexp $L$ 分割为 $T_r$ 个块 $L_1, \dots, L_{T_r}$,每个块大小为 $B_r$
- 对于每个 $i$,从 1 到 $T_r$,执行以下操作:
- 从 HBM 中将 $Q_i$ 加载到片上 SRAM
- 在片上初始化 \(O_i^{(0)} = (0)_{B_r \times d} \in \mathbb{R}^{B_r \times d}$,$\ell_i^{(0)} = (0)_{B_r} \in \mathbb{R}^{B_r}$,$m_i^{(0)} = (-\infty)_{B_r} \in \mathbb{R}^{B_r}\)
- 对于每个 $j$,从 1 到 $T_c$,执行以下操作:
- 从 HBM 中将 $K_j$ 和 $V_j$ 加载到片上 SRAM
- 在片上计算 $S_i^{(j)} = Q_i K_j^T \in \mathbb{R}^{B_r \times B_c}$
- 在片上计算:
- $m_i^{(j)} = \max(m_i^{(j-1)}, \text{rowmax}(S_i^{(j)})) \in \mathbb{R}^{B_r}$
- $\tilde{P}_i^{(j)} = \exp(S_i^{(j)} - m_i^{(j)}) \in \mathbb{R}^{B_r \times B_c}$(逐元素计算)
- $\ell_i^{(j)} = e^{m_i^{(j-1)} - m_i^{(j)}} \ell_i^{(j-1)} + \text{rowsum}(\tilde{P}_i^{(j)}) \in \mathbb{R}^{B_r}$
- 在片上计算: \(O_i^{(j)} = \text{diag}(e^{m_i^{(j-1)} - m_i^{(j)}})^{-1} O_i^{(j-1)} + \tilde{P}_i^{(j)} V_j\)
- 在片上计算: \(O_i = \text{diag}(\ell_i^{(T_c)})^{-1} O_i^{(T_c)}\)
- 在片上计算 logsumexp: \(L_i = m_i^{(T_c)} + \log(\ell_i^{(T_c)})\)
- 将 $O_i$ 作为输出的第 $i$ 个块写入 HBM
- 将 $L_i$ 作为 logsumexp 的第 $i$ 个块写入 HBM
- 返回输出 $O$ 和 logsumexp $L$
算法 2: FlashAttention-2 反向传播
输入要求:
- 矩阵 $Q, K, V, O, dO \in \mathbb{R}^{N \times d}$ 存储在 HBM 中
- 向量 $L \in \mathbb{R}^{N}$ 存储在 HBM 中
- 块大小 $B_c, B_r$
步骤:
- 将 $Q$ 分割为 $T_r = \lceil \frac{N}{B_r} \rceil$ 个块 $Q_1, \dots, Q_{T_r}$,每个块大小为 $B_r \times d$。将 $K, V$ 分割为 $T_c = \lceil \frac{N}{B_c} \rceil$ 个块 $K_1, \dots, K_{T_c}$ 和 $V_1, \dots, V_{T_c}$,每个块大小为 $B_c \times d$
- 将 $O$ 分割为 $T_r$ 个块 $O_1, \dots, O_{T_r}$,将 $dO$ 分割为 $T_r$ 个块 $dO_1, \dots, dO_{T_r}$,每个块大小为 $B_r \times d$,并将 logsumexp $L$ 分割为 $T_r$ 个块 $L_1, \dots, L_{T_r}$
- 初始化\(dQ = (0)_{N \times d}\) 并将其分割为 $T_r$ 个块 $dQ_1, \dots, dQ_{T_r}$。将 $dK, dV \in \mathbb{R}^{N \times d}$ 分割为 $T_c$ 个块 $dK_1, \dots, dK_{T_c}$ 和 $dV_1, \dots, dV_{T_c}$,每个块大小为 $B_c \times d$
- 计算 $D = \text{rowsum}(dO \circ O) \in \mathbb{R}^{d}$(逐元素相乘),将 $D$ 写入 HBM 并分割为 $T_r$ 个块 $D_1, \dots, D_{T_r}$,每个块大小为 $B_r$
- 对于每个 $j$,从 1 到 $T_c$,执行以下操作:
- 从 HBM 中将 $K_j, V_j$ 加载到片上 SRAM
- 在 SRAM 上初始化 \(dK_j = (0)_{B_c \times d}$,$dV_j = (0)_{B_c\times d}\)
- 对于每个 $i$,从 1 到 $T_r$,执行以下操作:
- 从 HBM 中将 $Q_i, O_i, dO_i, dQ_i, L_i, D_i$ 加载到片上 SRAM
- 在片上计算 $S_i^{(j)} = Q_i K_j^T \in \mathbb{R}^{B_r \times B_c}$
- 在片上计算 $P_i^{(j)} = \exp(S_i^{(j)} - L_i) \in \mathbb{R}^{B_r \times B_c}$
- 在片上更新 $dV_j \leftarrow dV_j + (P_i^{(j)})^T dO_i \in \mathbb{R}^{B_c \times d}$
- 在片上计算 $dP_i^{(j)} = dO_i V_j^T \in \mathbb{R}^{B_r \times B_c}$
- 在片上计算 $dS_i^{(j)} = P_i^{(j)} \circ (dP_i^{(j)} - D_i) \in \mathbb{R}^{B_r \times B_c}$
- 从 HBM 加载 $dQ_i$ 到 SRAM,然后在片上更新 $dQ_i \leftarrow dQ_i + dS_i^{(j)} K_j \in \mathbb{R}^{B_r \times d}$,并将其写回 HBM
- 在片上更新 $dK_j \leftarrow dK_j + (dS_i^{(j)})^T Q_i \in \mathbb{R}^{B_c \times d}$
- 将 $dK_j, dV_j$ 写入 HBM
- 返回 $dQ, dK, dV$
FlashAttention-2 并行化策略
前向传播并行化(Forward Pass)
FlashAttention 初始版本主要通过批次大小和头数实现并行化:
- 头数并行:每一个注意力头由一个线程块处理。
- 批次并行:总共有
批次大小 × 头数的线程块,每个线程块分配到流处理器(SM)上执行。 - 例如,在 A100 GPU 上有 108 个 SMs,当线程块数量很大(例如 ≥ 80)时,可以高效利用 GPU 上几乎所有的计算资源。
在处理长序列数据时(通常意味着批次大小或头数较小),为了更好地利用 GPU 上的多处理器,我们进一步在序列长度维度上实现并行化:
- 序列长度并行:外层循环(遍历序列长度)是完全可并行的,我们将它们安排在不需要相互通信的不同线程块上执行。
- 这种增加的序列长度维度的并行化有助于在批次大小和头数较小时提高 GPU 资源的占用率(occupancy),从而加速计算过程。
这种调整循环顺序(外循环遍历行块,内循环遍历列块,而非原始 FlashAttention 论文中的相反顺序)以及在序列长度维度上并行化的想法,最初由 Phil Tillet 在 Triton [17] 实现中提出并实施。
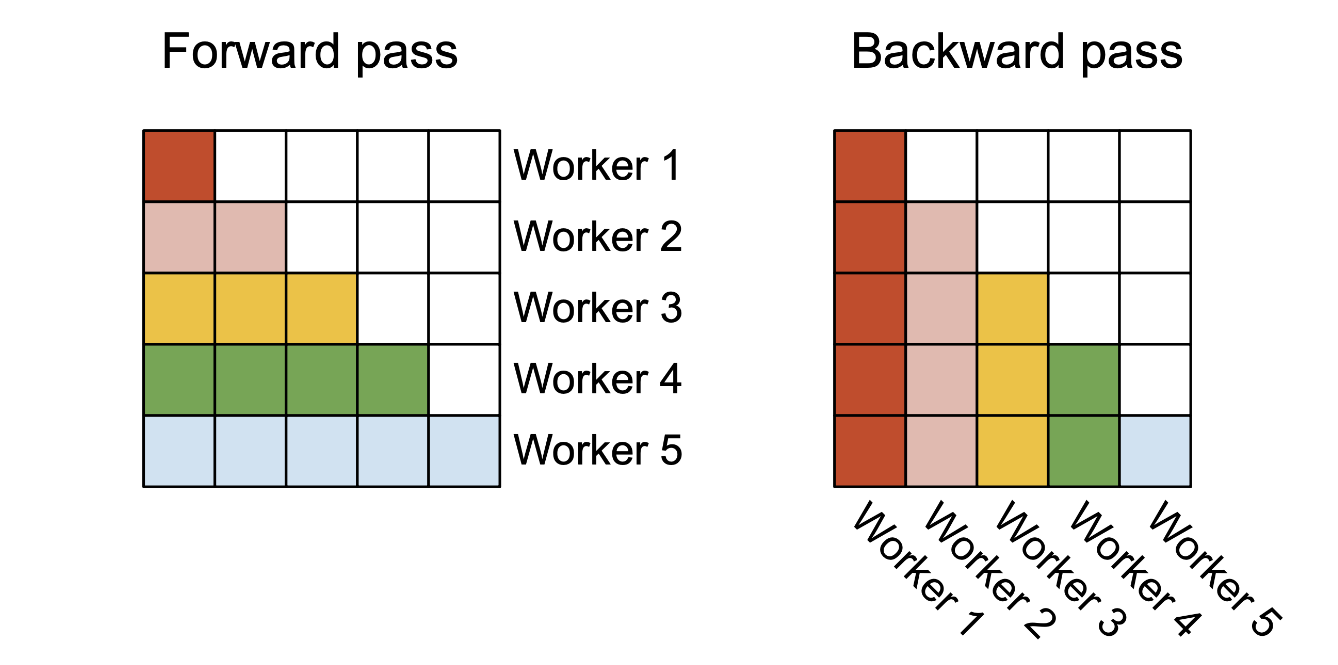
反向传播并行化(Backward Pass)
在反向传播中,不同列块之间唯一的共享计算发生在更新 $dQ$ 的步骤中:
- 我们需要从 HBM 加载 $dQ_i$ 到 SRAM,然后在片上更新 $dQ_i \leftarrow dQ_i + dS_j^{(i)} K_j$,并将其写回到 HBM。
- 同样,我们也在序列长度维度上实现并行化,为每个列块的反向传播安排一个线程块。
- 使用原子加法(atomic adds)在不同线程块之间进行通信,以更新 $dQ$。
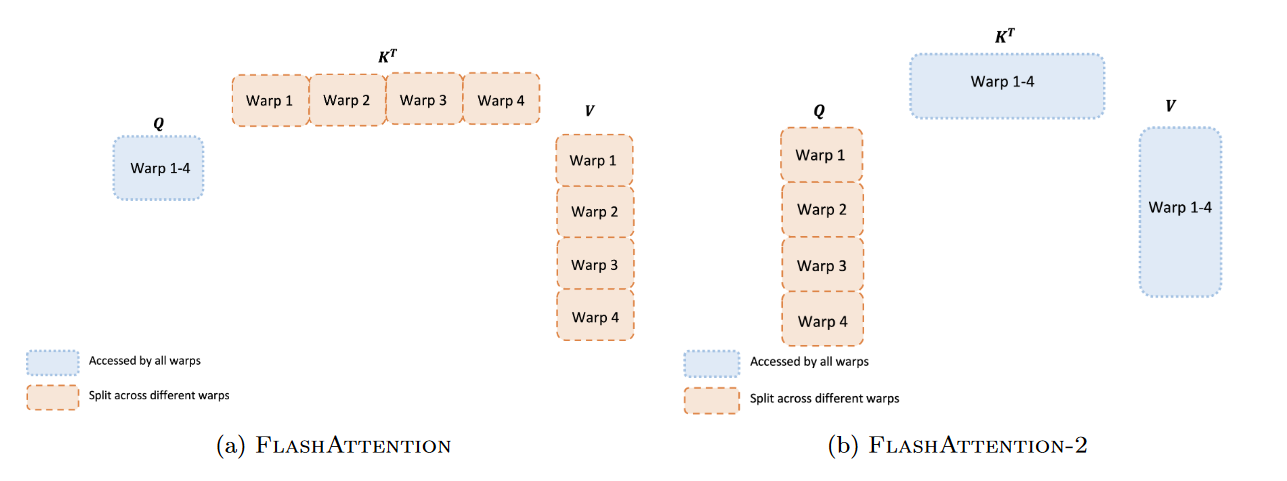
Warp 间的工作划分
前向传播(Forward Pass)
在前向传播中,我们需要在每个线程块(thread block)中划分工作给不同的 warps。通常,一个线程块使用 4 到 8 个 warps,工作划分如下:
- FlashAttention 中的划分:
- $K$ 和 $V$ 矩阵被分成 4 个 warp,而 $Q$ 矩阵是所有 warp 共享的。
- 每个 warp 计算 $QK^T$ 的一部分,然后再乘以 $V$ 的一部分,并通过共享内存同步结果。
- 这种方式称为 “split-K” 方案。然而,由于所有的 warp 都需要将中间结果写入共享内存,并在同步后相加,这会导致前向传播变慢。
- FlashAttention-2 中的优化:
- 在 FlashAttention-2 中,我们对 $Q$ 矩阵进行划分,分给 4 个 warp,而 $K$ 和 $V$ 矩阵则由所有 warp 共享。
- 每个 warp 计算 $QK^T$ 的一部分,然后直接乘以 $V$ 的对应部分来得到最终输出。
- 这种方法不需要 warp 之间进行通信,减少了共享内存的读写操作,因此加速了计算。
反向传播(Backward Pass)
对于反向传播,FlashAttention-2 也避免了 “split-K” 方案,减少了 warp 之间的同步。然而,由于反向传播涉及更多复杂的依赖关系(比如 $Q, K, V, O, dO, dQ, dK, dV$ 等),还是需要一定的同步操作。不过,避免 “split-K” 依然有效地减少了共享内存的读写操作,并加速了反向传播。
调整块大小(Block Sizes)
调整块大小也能影响计算效率:
- 减少共享内存的加载/存储:增大块大小可以减少共享内存的读写操作。
- 寄存器需求和共享内存限制:随着块大小的增加,寄存器和共享内存的需求也增加。如果块大小过大,可能会导致寄存器溢出,从而显著减慢计算速度,甚至导致 GPU 无法运行该计算内核。
通常,选择块大小为 {64, 128} × {64, 128},具体选择取决于注意力头的维度 $d$ 和设备的共享内存大小。虽然我们可以手动调整这些块大小,但自动调优(auto-tuning)可能更高效,未来的工作可以对此进行进一步优化。
Leave a comment